The previous article provided an introduction to unit testing in general covering the purpose and benefits of unit testing. This article now looks at a method of unit testing that can be utilised in a SAP DataServices project. First we’ll discuss what objects are candidates for unit testing and then look at how we implement the unit testing of these objects.
What objects are unit tested in SAP Data Services
If the “unit” in unit testing is the smallest piece of executable code what are the units in a SAP Data Services (SDS) project?
What is ‘executed’ in SDS are jobs so are then jobs units? Not necessarily as the job itself can be complex and execute many workflows, dataflows and scripts and so the job can be broken down into smaller areas of functionality. Similarly workflows are not candidates for unit testing as they can contain several dataflows and scripts. Dataflows, scripts and custom functions are areas of code that can’t be broken into a smaller unit and so are therefore candidates for unit testing. It is possible create a dataflow that performs a series of complex transformations and as such testing each transformation in isolation would be desirable. However as yet SDS does not yet provide a mechanism specifically for this; although embedded Dataflows can be used to break up a large, complex dataflow they are difficult to execute and unit test in isolation.
Therefore in SDS the objects that can be unit tested are,
- scripts
- custom functions
- dataflows
SDS contains other objects such as datastores and file formats however these are static in nature and so are not candidates for unit test. The unit tests for dataflows will highlight any defects with a datastore or file format.
Unit Test Automation
Although automation of a unit test is not essential as the test can always be done manually it does have some key benefits. Automation ensures consistency in the unit test in that every time the test is run the exact same tests are applied. In addition automation also reduces the overall development and system testing effort. As we will see there is some effort required to build the automated unit test however effort is saved later on when the re-execution of unit tests become just a single click and the automated unit tests naturally lead to building a regression pack.
In the following section we will look at how to construct a unit test for dataflows, custom functions and scripts in turn and also look at how to construct an automated unit test.
Unit Testing Dataflows
Dataflows can be unit tested by reusing the dataflow in a new Job that is created specifically for unit testing. A job in SDS may consist of many workflows and dataflows and executing the entire job is therefore impractical for unit testing. However SDS allows the reuse of components such as dataflows in more than one job and we can exploit this in order to create our unit test jobs. In the illustration below we have a schematic of a production job where a series of data flows load data from source systems into a staging area followed by dataflows that move the data into the historical data store (HDS) and finally into the data mart. Also displayed are separate unit test jobs where the dataflows of the main job are reused individually in separate jobs.

Just reusing the dataflow in another job for unit testing is usually not enough as we want to automate the unit test and we also need to remove any dependencies that the dataflow has with any other dataflows or scripts in the main production job. So first of all we’ll look at how to remove these dependencies followed by how we then automate the unit test.
Eliminating Dependencies
Dependencies can exist where a result or calculation made at one point in the job is then used by the dataflow under test, for example, a script at the start of a job sets some global variables that are then later used by the dataflow. Or a table loaded by one dataflow is used as a source for a later dataflow. When unit testing we don’t want to have such dependencies for two reasons,
- if the script or function is defective then the unit testing of the dataflow is blocked until this is resolved.
- another developer may have the task of producing the custom function and these may not have been written or as the developer changes this script of function we then need to ensure that we have latest version in our code line
Consider a dataflow that is required to load the target table with a batch number and batch date where these identify the daily loads to our data warehouse. In production the batch date will typically be based on the system date and the batch number would be some unique incremental number. In the job a script runs before a dataflow that obtains these values, something like,
$vBatchDate = getBatchDate(); $vBatchNumber = getBatchNumber();
Here we have a dependency between the dataflow and the script that generates the batch date and number and we need to remove this dependency in order to be able to unit test the dataflow.
To do this we use a different script in our unit test job and hard code the values for batch number and batch date.
$vBatchDate = to_date('01/01/2010','DD/MM'YYYY');
$vBatchNumber = 1;
So our production job contains a script that executes before the dataflow that generates required batch date and batch number while in our unit test job we use a different script that uses a hard coded batch date and number.

Using a hard coded fixed value for the batch date and number in the unit test job makes sense as we need the unit test to be consistent and as we’ll see later this is also necessary if we want to automate the checking of the unit test results. The variables are local variables and parameter calls are used to pass the values to the dataflow. Although global variables can be used it is not recommended as using global variables can hide dependencies between separate areas of code [8].
This script that we add at the beginning of the unit test jobs is referred to as the initialisation script and we’ll see more uses of this script later.
Dependencies on Environmental Settings
A second example of where dependencies arise is when using environmental values such as system date, here our dependency is not so much on another part of the job but instead we are depending on an environment state.
For example if a dataflow filters to only select “this weeks” data then the source data that is being used for unit testing would need to have some records that fall within this week and some that don’t. The obvious limitation here is that as the weeks go by we’ll need to keep updating our source test data set in order for the range of dates to cover the current week when we’re running the test.
Often a dataflow would add a where clause to the query to filter the data to the current week, for example, in DB2 we may have a condition similar to,
WHERE YEAR(trans_date) = YEAR(CURRENT DATE) AND WEEK(trans_date) = WEEK(CURRENT DATE)
The solution here is to replace the use of the system date function (CURRENT DATE above) within the dataflow with a regular variable,
WHERE YEAR(trans_date) = YEAR($vFilterDate) AND WEEK(trans_date) = WEEK($vFilterDate)
Then set the variable to the value of the system date in a script ahead of the dataflow. Then in the unit test the dataflow is reused in the unit test job but now a different script is used to set the variable to a known fixed value.
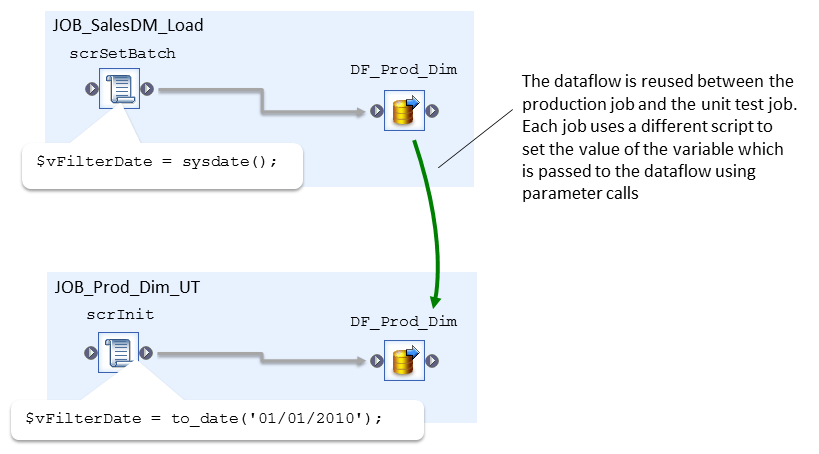
We now have a unit test job for dataflows that can be run manually and results checked however what we want is to automate the unit test and the next section looks at how we can do this.
Automating a Dataflow Unit Test
An automated unit test of a dataflow would consist of executing the dataflow’s unit test job and have the job itself output whether the test has passed or failed. There are two aspects required for automation: the first is that the data set used in the dataflow processes (both source and target) is consistent for each execution of the unit test and secondly the unit test itself needs to perform a check of the results and output “pass” or “fail”.
This is achieved through use of two key scripts: an initialisation script that runs before the dataflow and a check results script that runs after the dataflow. The initialisation script, typically labelled scrInit, is responsible for preparing the unit test. We have seen an example of initialisation above where we hardcode parameters required by the dataflow. Another initialisation activity is preparing the source and target data for the dataflow. This preparation of the test data is the key to ensuring consistency between successive unit tests. The check results script, labelled scrCheck, checks the results of the dataflow execution and reports whether an individual test within the unit test has passed or failed. Our unit test job now looks like,
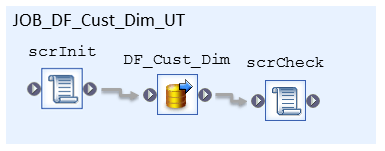
Initialisation Scripts
The initialisation script is responsible for preparing the unit test and this typically involves.
- Setting values to parameters used in the dataflow
- Preparing the inbound dataset
- Preparing the target table
Using a dataset that is always the same for all unit tests is necessary to ensure that the unit test is consistent between tests. Consistency ensures that for successive executions, whether by same developer at different times or by different developers, the same results will be generated. This consistency ensures that as code is updated we then identify any defects that may have crept into the code.
Source data
The source data set is either one or more tables or flat files. Managing a consistent source file is relatively easy to do: we just create the file and save it in a folder specifically for holding unit test data. Within the file format used in the dataflow a parameter is used to define the location and filename of the file being loaded – the initialisation script defines this parameter and in the production job a different script defines the location in the production environment.
If we have a dataflow that is loading from a source table to a target table then we ensure that the source table contains a consistent set of data. Ideally each developer should be allocated their own database, or schema, and so are isolated from each other. Each developer then maintains the data in the source table required for the unit test. It is common that a target table for one data flow acts as a source table for another dataflow. In this situation we won’t be able to maintain the target table data as this is going to be overwritten when executing the unit test for the preceding dataflow. To overcome this we maintain the data elsewhere, in another table or flat file say, and then the initialisation script loads this data into the table prior to execution of the dataflow.
Hand Crafted Test Data
Unit testing is “white box” testing, that is, the tests deliberately reflect the functionality in the dataflow under test. This then requires that the source data set used must contain enough different rows of data such that all the required functionality is tested
For example consider a dataflow that is required to reject rows that have a null value in a certain column. We prepare our source data such that it does contain rows that have a null value and some rows that don’t. Then in our unit test we check that the required number of rows have been loaded and rejected.
Therefore it is common to manually prepare the test data required by the unit test must either by updating some sample data or creating the data from scratch.
Target Data
It is also important to ensure that the target table also contains the same dataset. If, for example, we are testing a dataflow that is performing a Changed Data Capture (CDC) routine then we need some data in our target table in order to test that our updates, deletes and inserts perform as expected. In other cases we need to start with an empty target table. Again the initialisation script is used to prepare the target data.
So in summary the initialisation script prepares the unit test and this includes,
- Hard coding parameters required by the dataflow
- Preparing inbound data sets either in flat files or in tables
- Preparing the target data set either truncating the target table or populating with a defined data set
Check Scripts
The second script we use in an automated unit test is a script that checks the results after the dataflow is executed and reports pass or fail for each check. This typical involves examining the data loaded or updated into the target table and is best explained by an example.
In this example a dataflow is loading a single table of customer data into a customer dimension in a data warehouse. The source data set has two separate columns for first name and last name and our requirement is to combine this data into a single customer name column. Through data profiling we know that some source data is missing first name and some data is missing last name and some data doesn’t have either populated so our technical requirement is,
- Where both first name and last name are present load first name + space + last name to the customer name column
- Where first name is missing but last name is present load only last name to customer name column
- Where last name is missing but first name is present load only first name to customer name column
- Where both first name and last name are missing then load “unknown” to customer name column
Hence from this there are four different data scenarios that need to be implemented within our data flow and consequently there are four checks we need to make within our unit test.
For a unit test we prepare a set of source data within which there is a row that matches one of the above required scenarios such as can be seen in the following table,
| CUSTOMER_ID | FIRST_NAME | LAST_NAME |
|---|---|---|
| 1 | John | Brown |
| 2 | Smith | |
| 3 | Alison | |
| 4 |
When this data is loaded then the following table is what we expect to get and therefore our unit test check script explicitly checks for this result,
| CUSTOMER_ID | CUST_NAME |
|---|---|
| 1 | John Brown |
| 2 | Smith |
| 3 | Alison |
| 4 | Unknown |
An example of such a check script can be seen below. There are four similar bits of code in the check script with each one checking that one of the four required scenarios has been implemented correctly. So the first bit of code checks for the first scenario which is the case when both first and last names are populated we get the correct result in the CUST_NAME column of first name and last name concatenated together with a space.
$vResult = sql('DS_DATAMART', 'select CUST_NAME from DIM_CUSTOMER ' ||
'where SRC_ID = 1');
if($vResult = 'John Brown')
print('PASS : Test 1');
else
print('FAIL : Test 1 : "John Brown" expected [$vResult] found.');
$vResult = sql('DS_DATAMART', 'select CUST_NAME from DIM_CUSTOMER ' ||
'where SRC_ID = 2');
if($vResult = 'Smith')
print('PASS : Test 2');
else
print('FAIL : Test 2 : "Smith" expected [$vResult] found.');
$vResult = sql('DS_DATAMART', 'select CUST_NAME from DIM_CUSTOMER ' ||
'where SRC_ID = 3');
if($vResult = 'Alison')
print('PASS : Test 3');
else
print('FAIL : Test 3 : "Alison" expected [$vResult] found.');
$vResult = sql('DS_DATAMART', 'select CUST_NAME from DIM_CUSTOMER ' ||
'where SRC_ID = 4');
if($vResult = 'Unknown')
print('PASS : Test 4');
else
print('FAIL : Test 4 : "Unknown" expected [$vResult] found.');
Print statements are used to output the results and so after the unit test job has been executed a quick scan of the generated log file will tell you whether the dataflow has passed all tests of if some have failed. To help with debugging the print statements for the fail case display the value that is expected along with what was actually received.
Summary
Above we looked at what activities are required in order to create automated unit tests for dataflows. This involves,
- Creating a new job specifically for unit testing the dataflow
- Reusing the dataflow from the original job in the unit test job
- Eliminating any dependencies between the dataflow and any other aspects of the production job
- Preparing a suitable unit test data set
- Adding the initialisation script to the unit test job to prepare the test data and any parameters
- And finally adding the check results script
As well as dataflows we also identified custom functions and scripts as objects that can also be unit tested the next section looks at how we unit test these.
Unit Testing Custom Functions
To perform a unit test of a Custom Function a job is created that contains a script which executes the custom function. The script provides a set of known input parameters to the custom function and then checks that the return value is what is expected. For example if the custom function getRecordCount(tablename) returns the number of rows for a given table then the unit test script first populates a table with a fixed number of rows, then executes the custom function and finally checks that the return value is the same as the number of rows that were populated in the table.
In the example script below we empty and populate the target table then check that the custom function under test returns the number of rows expected.
# empty target table
sql('DS','truncate table cust_dim');
# populate with data
sql('DS','insert into cust_dim select * from cust_dim_ut');
# get row count
$vResult = getRecordCount('cust_dim');
# check result
if($vResult = 25)
print('PASS : Test 1');
else
print('FAIL : Test 1 : "25" expected [$vResult] found.');
Custom functions can however be more procedural in nature, that is, they do something rather than return values. A common example is to create a custom function that wraps the moving of a file of the operating systems file system. Here our test would be then to check that the function did indeed move the file correctly.
Scripts
Scripts are often used in SDS to perform some sort of routine functionality such as moving files on the file system, writing to log files, initialising variables and other such operational functionality. If a script is quite simple, for example, initialising the value of a variable then these probably do not need to be explicitly tested in isolation but can be tested along with a Dataflow. More complex scripts should be unit tested.
In SDS it isn’t possible to execute a script on its own and so for unit testing we need to look how to isolate the script so that it can be tested. This is best explained by example.
Consider a job that consists of a script followed by a dataflow. The script reads values from a properties table in a database and passes these as parameters to the dataflow.

The unit test of the script is to check that the correct values are read from the properties table. In order to perform a unit test of the script in isolation (i.e. without also executing the dataflow) we embed the script within a workflow and then we can create a unit test job that contains the workflow. So our original job is now our workflow that contains our script followed by the dataflow. Note, parameter calls are required in order to pass the values in the script up through the workflow to the dataflow.
We can then create a unit test job that just executes the workflow containing the script and in this job we can add another script to display or check the values that the script obtained from the properties table. The project structure is displayed below,

The image below is of the unit test job and this contains the workflow followed by the script that checks the script results.

The original job contains the same workflow followed by the dataflow and is illustrated below.

So in summary in order to unit test scripts we embed the script within a workflow so that the script can be shared between the original job and a unit test job.
If a script is looking difficult to unit test then this may indicate that your overall design should be improved. For example a script that is performing several distinct activities should be split up (this leads to better structured, more manageable code and increases code reuse) or maybe some or all of the script would be better as a custom function (which also encourages code reuse).
Test Suites
A test suite is a single job that executes a series of unit tests, typically covering an entire ELT process, for example, all the data flows that load a subject area within the data warehouse. Executing the test suite then checks the whole system and as such acts as a regression pack [http://softarc.blogspot.co.uk/2008/06/automated-regression-testing-why-what.html] for the system and typically this is executed prior to the packaging release of the system from development to test.
To create a test suite the objects of the unit test need to be moved into a workflow, that is, the initialisation script, check script and the dataflow under test,

Then we can build our test suite job by including these workflows in the test suite job. Note, although we could run the workflows in parallel we instead run them sequentially so that the print statements from the check result scripts are grouped together and are not intermixed.

We still retain the original unit test jobs so that we are able to run a unit test on a single dataflow or object and the main use for the test suite above is to provide a regression pack which is typically run prior to the packaging and promotion of the complete ETL code to system test.
At this point we can improve the print statements in the check scripts so that we can easily identify which unit test generated the result and for this we can just include the workflow name. So if we continue with our example above we can update this to,
if($vResult = 'John Brown')
print('[workflow_name()] : Test 1 : PASS');
else
print('[workflow_name()] : Test 1 : FAIL :
"John Brown" expected [$vResult] found.');
Log Results to a Database
An enhancement that can be made is to write the unit test results into a database from which they can then be analysed to produce overall metrics on the unit test process. This is fairly straightforward to do and essentially involves creating a new dataflow that executes at the end of the test suite which reads the log file, parses it and then writes the data to the required table.
The print statements must have a consistent structure so that they can be readily parsed, for example, the example print statements above use colons to delimit the text and always write out the same information in the same order. Therefore a simple File Format can be created that automatically separates out the parts of each print statement into columns which are then easily loaded in the database. A good way of ensuring consistency in the print statements is to create a custom function that wraps the print statements and takes separate parameters for each of the components to be printed,
print_unit_test(pUnitTestName as varchar, pTestNumber as int,
pPassFail as int, message as varchar);
Conclusion
Unit testing is an essential part of any software development process and software developed using SAP Data Services is no different. Creating automated unit tests can bring significant benefits to a project, in particular improved overall quality through identification of defects and reduced overall cost as defects are found earlier in the system development life cycle.
This article described an approach for unit testing in SAP Data Services that is robust, repeatable and through a simple extension allows the test results to be written to a database so that they can be readily analysed.
I hope you found the article informative and that you consider implementing unit testing in your project!

4 thoughts on “Automated Unit Testing in SAP Data Services. Part II”